8.6 Swarm 高可用与负载均衡

在 Docker Swarm 集群中,高可用性(High Availability) 和 负载均衡(Load Balancing) 是两个核心特性。
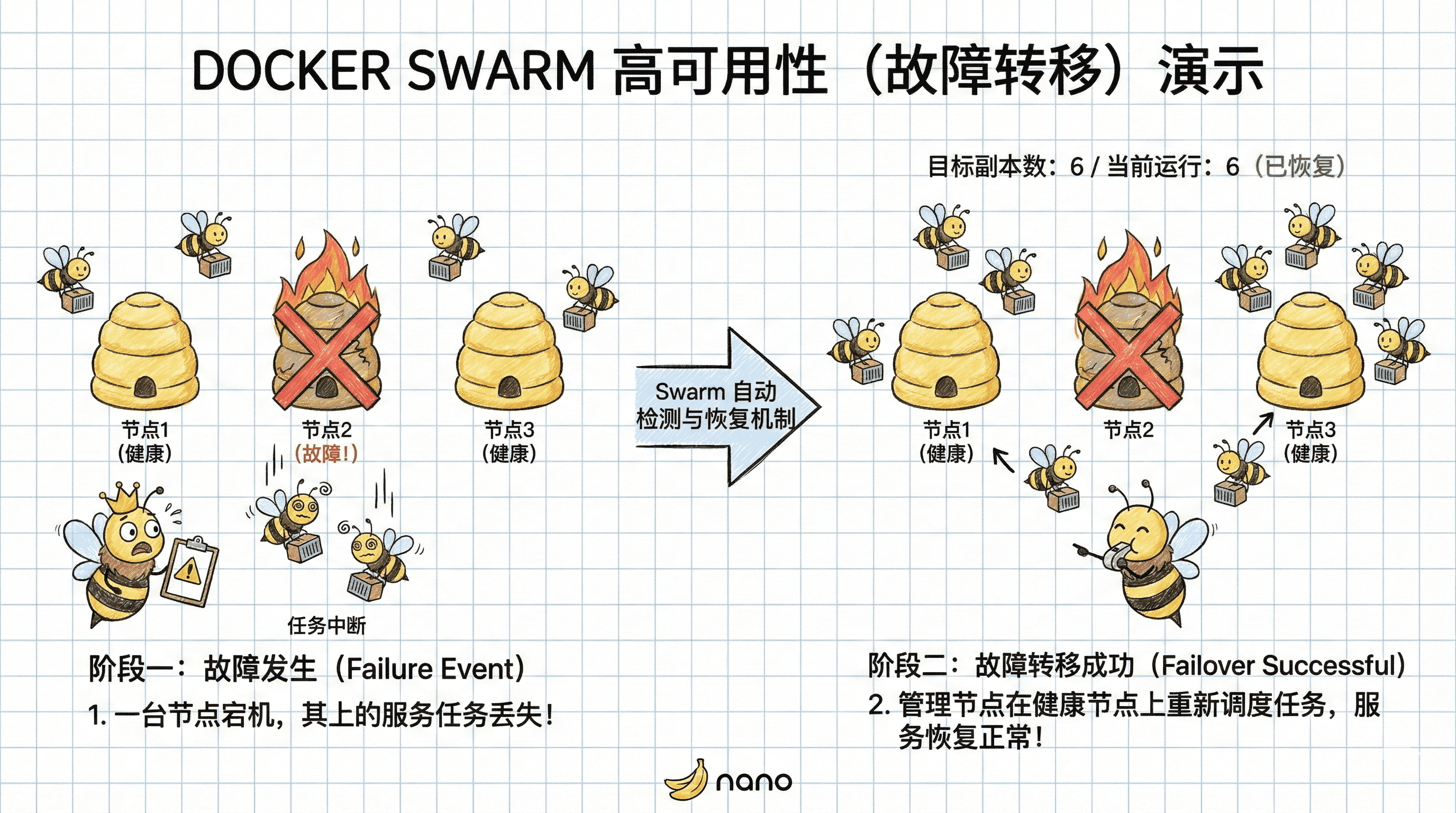
- 高可用:当集群中的某个节点发生故障时,Swarm 会自动检测并将其上运行的任务调度到其他健康节点,确保服务不中断。
- 负载均衡:Swarm 将访问流量自动分发到后端的各个容器副本。
任务一:验证高可用性
1. 创建服务
首先,创建一个拥有 2 个副本(Replicas)的服务,模拟一个需要高可靠运行的应用。
执行以下命令:
docker service create \
--replicas 2 \
--name s[学号后两位] \
-p [8000+学号]:80 \
-e STUDENT_ID=[学号] \
harbor.seahi.me/stu/whoami-for-swarm--replicas 2:告诉 Swarm 我们希望始终有 2 个容器实例在运行。
2. 查看任务分布
查看服务中的任务目前运行在哪些节点上:
docker service ps s[学号后两位]你会看到两个任务分别运行在不同的节点上(例如 manager-1 和 manager-2)。Swarm 默认会尽量将任务分散到不同节点。

3. 模拟节点故障
为了验证高可用,我们模拟其中一个节点发生故障。假设其中一个任务运行在 manager-2 上,我们登录到该节点并停止 Docker 服务:
# [在 manager-2 节点上执行]
systemctl stop docker4. 验证服务自愈
回到主节点(Manager Leader),再次查看任务状态:
docker service ps s[学号后两位]
你会发现:
- 原来运行在
manager-2上的期望状态变成了Shutdown,当前状态为Running但节点已失联)。 - Swarm 检测到了节点丢失,立即在另一个健康节点(如
manager-3)上启动了一个 新任务(拥有新的 ID)。 - 最终结果:服务的可用副本数恢复到了 2 个,业务未受持续影响。
s00.1 的状态依然显示为 Running,这是因为 Swarm 的节点心跳检测有一定的超时时间,此时管理节点还没判定它完全“死亡”,但为了保险起见,它已经启动了新任务。实验结束后,请务必恢复 manager-2 的 Docker 服务:
# [在 manager-2 节点上执行]
systemctl start docker任务二:VIP 与外部负载均衡器
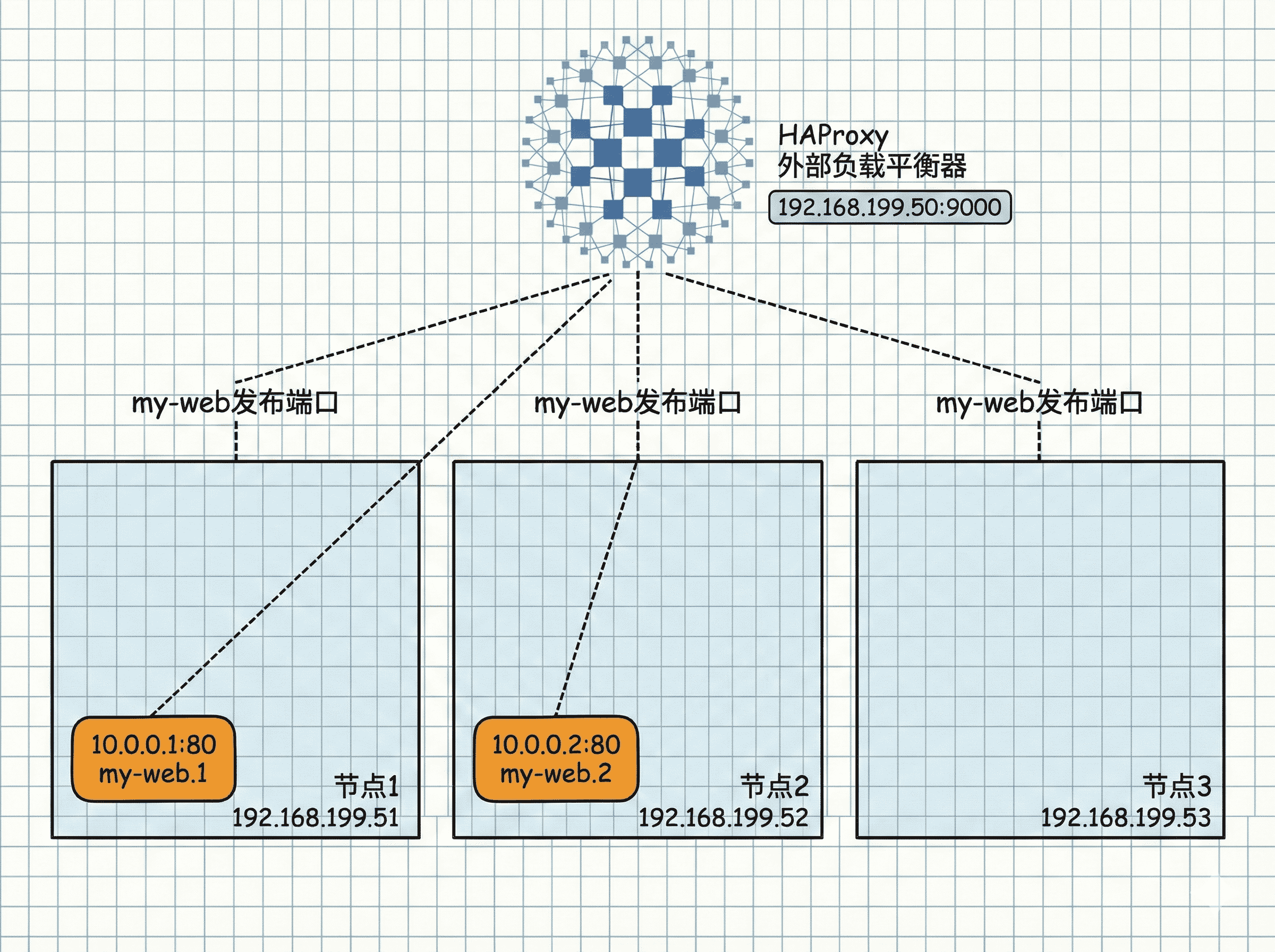
虽然 Swarm 自带了 Routing Mesh(路由网格),但我们也可以在集群外部再部署一个负载均衡器(如 HAProxy 或 Nginx),作为流量的统一入口。
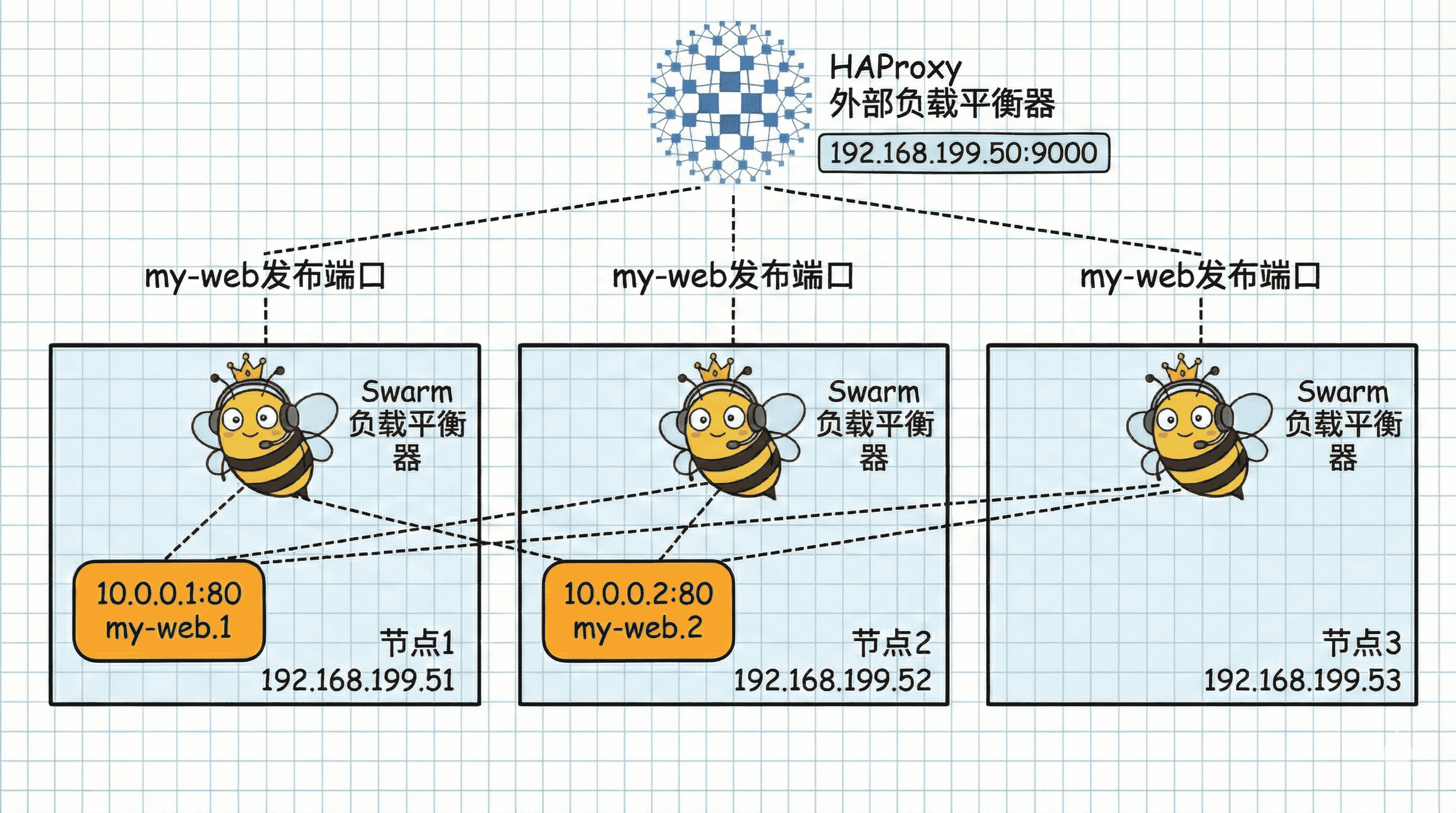
1. 扩容服务
将刚才的服务扩容为 3 个副本,尽量保证每个节点都有任务:
docker service scale s[学号后两位]=3查看任务分布,确认每个节点都在运行。

2. 准备 HAProxy 配置
我们将使用 HAProxy 作为外部负载均衡器。
创建配置目录:
mkdir /srv/haproxy
cd /srv/haproxy在该目录下创建名为 haproxy.cfg 的配置文件:
内容如下:
defaults
mode http
# 前端设置
frontend http-in
# HAProxy 监听的端口
bind *:[9000+学号后两位]
default_backend servers
# 后端设置
backend servers
balance roundrobin
# 这里填写 Swarm 集群节点的 IP 和服务暴露的端口
# 即使某个节点上没有运行该容器,Swarm 的路由网络也会自动转发流量
server node1 192.168.192.199:[8000+学号后两位] check
server node2 192.168.192.202:[8000+学号后两位] check
server node3 192.168.192.203:[8000+学号后两位] check3. 运行 HAProxy
在主节点上启动 HAProxy 容器(一般在独立于集群的外部设备上部署 Haproxy):
docker run -d \
-v /srv/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg \
-p [9000+学号后两位]:[9000+学号后两位] \
--name haproxy-[学号后两位] \
haproxy4. 验证效果
在浏览器中访问 http://<主节点IP>:[9000+学号后两位]。
多次刷新页面,观察结果:

你会发现虽然访问入口不变,但提供服务的容器(Hostname 和 IP)在不断变化,这证明负载均衡正在工作。
5. 清理环境
删除集群中的服务与 HAProxy 容器
任务三:DNSRR 与外部负载均衡器
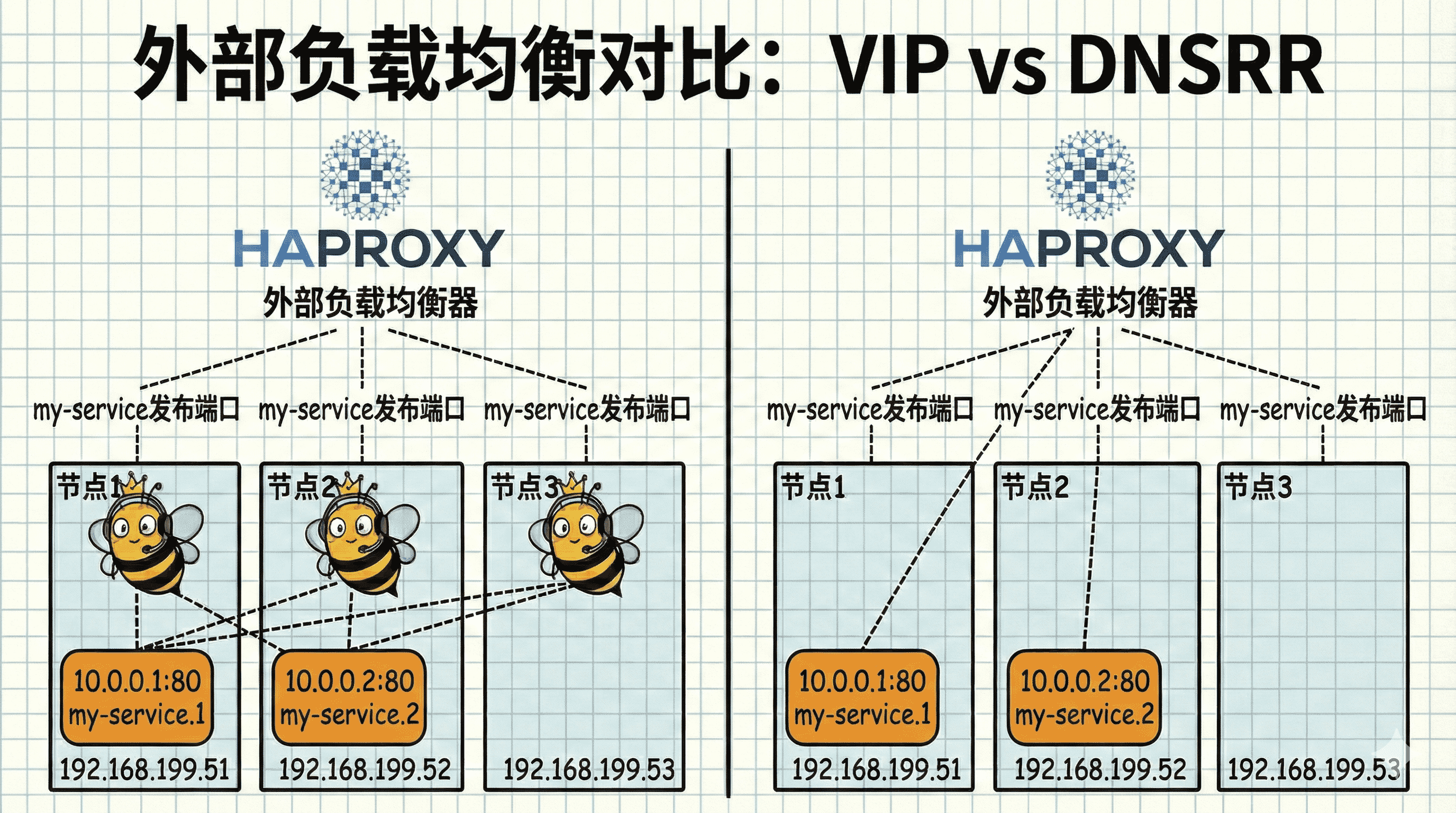
1. 什么是 DNSRR?
在前面的任务中,Swarm 使用 VIP 模式,所有容器共用一个虚拟 IP。
但在某些场景下,我们需要直接获取每个容器的真实 IP 地址,比如:
- 使用外部负载均衡器时,需要知道每个容器的具体位置
- 某些应用需要直连到特定的容器实例
这时就可以使用 DNSRR(DNS 轮询) 模式。
-p 端口映射(Routing Mesh 失效)。它主要用于集群内部通信。在本任务中,我们将创建 DNSRR 服务,并使用 HAProxy 直接连接到每个容器的真实 IP 进行负载均衡。
2. 创建 DNSRR 服务
创建一个指定 endpoint-mode 为 dnsrr 的新服务。我们需要先创建一个 overlay 网络,以便容器间通信:
# 创建 overlay 网络(添加 --attachable 参数允许单机容器连接)
docker network create -d overlay --attachable dnsrr-[学号后两位]
# 创建 DNSRR 服务(3 个副本)
docker service create \
--name s[学号后两位] \
--replicas 3 \
--network dnsrr-[学号后两位] \
--endpoint-mode dnsrr \
harbor.seahi.me/stu/whoami-for-swarm查看服务状态:
docker service ps s[学号后两位]
3. 获取容器真实 IP
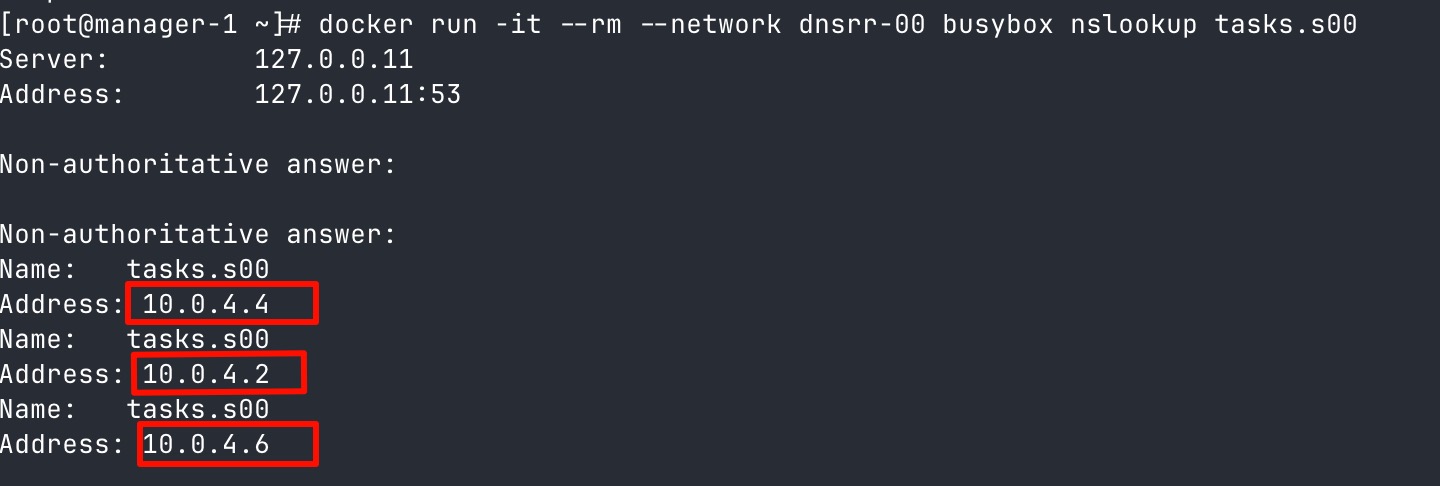
在 Swarm 的 dnsrr 模式下,Docker 专门预留了一个 DNS 记录前缀叫 tasks.。使用 nslookup 命令获取所有容器的真实 IP 地址:
# 启动一个 busybox 容器并执行 nslookup
docker run -it --rm --network dnsrr-[学号后两位] busybox nslookup tasks.s[学号后两位]你将看到 DNS 解析返回了 3 个不同的 IP 地址,而不是原来的 1 个 VIP:
4. 准备 HAProxy 配置
修改 haproxy.cfg 的配置文件,内容如下:
defaults
mode http
# 前端设置
frontend http-in
# HAProxy 监听的端口
bind *:[9000+学号后两位]
default_backend dns-servers
# 后端设置
backend dns-servers
balance roundrobin
# 这里填写从 nslookup 获取的容器真实 IP
# 注意:容器默认监听 80 端口
server container1 10.0.4.4:80 check
server container2 10.0.4.2:80 check
server container3 10.0.4.6:80 check5. 运行 HAProxy
启动 HAProxy 容器,并将其加入到与服务相同的 overlay 网络:
docker run -d \
-v /srv/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg \
-p [9000+学号后两位]:[9000+学号后两位] \
--network dnsrr-[学号后两位] \
--name haproxy-[学号后两位] \
haproxydnsrr-[学号后两位] 网络,才能访问到容器的真实 IP。6. 验证效果
在浏览器中访问 http://<主节点IP>:[10000+学号后两位]。
多次刷新页面,验证负载均衡是否正常工作。
- 任务二:HAProxy → Swarm 节点(VIP) → 容器
- 任务三:HAProxy → 容器真实 IP(直连)
在 DNSRR 模式下,HAProxy 可以直接连接到每个容器的真实 IP,不再依赖 Swarm 的 VIP 机制。